購入のキッカケは、なんとなくNASが欲しくなったこと。 ShuttleのKD21と 散々悩んだんだけど、購入決定時にKD21は発売まであと一週間あったこと、KD20の 時にShuttleはファームウェア周りで色々やらかしてくれてるのを鑑み、安定動作こそ我が命! ということで、既に枯れ枯れに枯れちゃってるはず(※発売日は2011/10)の コレを選択したわけで。最新ファームウェアのリリース日が2013/07/31というごく最近なのも、 「長いことサポートしまっせダンナ」的な姿勢が見えて好印象。ついでに、2.0TBの ハードディスクx2付属でAmaz○nで22500円とかで入手できるのもお買い得感高い。 前面USBが2.0なのはちょっとマイナス評価だが、それが何だというのだ! もうコレしかない!…というような頭悪い葛藤があって、入手したのですよ HDL2-A4.0を。I-O DATAさんありがとう!なんか楽しいよコレ!
なお、本ページは我輩所有のHDL2-A4.0についてのみ述べていて、HDL2-A2.0とか HDL2-A6.0とかは対象外なので注意。HDD容量以外は全部同じだろうけれど。
このページの情報は一切無保証で、誤っている可能性もあることを 先に了承すること。このページを見て操作した挙句、アナタに何か不利益な ことが起こったとしても、我輩は一切それに関知しない。何もかも自己責任だし、 I-O DATAの保証の範囲を超える可能性が極めて高いので注意。 何かあったときに間違っても(我輩はもとより)I-O DATAにご迷惑をかけないこと! 我々ユーザはメーカーの手のひらの上で踊る卑しい哀れな孫悟空だと自認し、 孫悟空は孫悟空らしく、世界のすみっこでちっちゃく楽しむのが吉。
本機は、ARM Linux(kernel-2.6ベース)を採用している。恐ろしいことに、 内部にフラッシュメモリなどのOS起動用の領域は存在しない。 OS起動領域は全てHDD上に格納されており、従って、二つのHDDが両方破損した場合、 これを復旧する手段は無い。実に男らしい。 I-O DATAに元のHDDごと送れば、実費で交換してくれることはあるらしい。 だけど、面倒だし結構お金かかるしI-O DATAにもお手間取らせてしまうので、 ユーザの皆様におかれましては、両方破損しないようにご注意を。 後述する方法で、予めシステム部分のバックアップをとっておくもよし。
なお、HDDが片方だけ破損しても、OS領域はミラーリングされているので 復旧は可能(ただしRAID0の場合はデータ部分は消えてなくなる)。
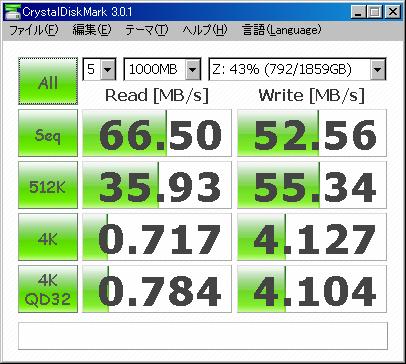
ちなみに、初期状態(RAID1でフォーマット)でのCrystalDiskMarkの結果はこんな。 安物HUB経由してるのに頑張ってるじゃぁないの。さすが高速を謳うだけある! (100MB/sは言いすぎな気がするけど)。
…ところで、起動に三分もかかるのはどうにかなりませんかのぅ。 Embeded Linuxで三分て。
そっか、Debianかー…。我輩あんま使ってないんだよなー…。 コンパイルした人がsekiya@devsrvとなっているということは、これは自前でコンパイル して作ったということだろう。ニホンジンっぽいお名前が見えてなんか嬉しい。
HDL2-A4.0の初期状態では、ディスクのパーティションは以下のように構成されていた。 最初からGPTとは剛毅なことよ!(3TB HDDモデルがあるから当然か)。 ちなみに、RAID0でもRAID1でもこの構成は同じだし、左右のHDDいずれも同じ状態 (後述するが、中身は左右でほんの少し違うみたい)。 RAID0/RAID1の切り替え時には、/dev/sda6だけをLinuxのSoftraid(MD...Multiple DisksのRAID0 or RAID1)でストライピング・ミラーリング構成する。
# parted -s /dev/sda print Model: ATA ST2000DM001-1CH1 (scsi) Disk /dev/sda: 2000GB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 20.5kB 537MB 537MB ext3 primary 2 537MB 1611MB 1074MB primary 3 1611MB 3758MB 2147MB linux-swap primary 4 3758MB 3892MB 134MB primary 5 3892MB 4429MB 537MB primary 6 4429MB 2000GB 1996GB primary |
セクタ単位で表示するとこんなカンジ。この方が正確にわかるよね。4KB/Sectorの 場合どうなるのかなぁと思ってたけど、スタートセクタは全て8で割り切れるので、 ちゃんと4KB/SectorのHDDにもコピーできそうな予感。
# parted -s /dev/sda u s print Model: ATA ST2000DM001-1CH1 (scsi) Disk /dev/sda: 3907029167s Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 40s 1048623s 1048584s ext3 primary 2 1048624s 3145783s 2097160s primary 3 3145784s 7340095s 4194312s linux-swap primary 4 7340096s 7602247s 262152s primary 5 7602248s 8650831s 1048584s primary 6 8650832s 3907029127s 3898378296s primary |
このうち、先頭から5個目までのパーティションには、HDL2-Aが起動するために必要な システム(ARM Linux本体)が入っているので、変更してはならない。最後の でっかいパーティションがデータ用のもの。
フォーマット直後、6番目のデータパーティションを別のLinuxシステム上で /mnt/hddにmountして、 ls-alR /mnt/hdd した時の実行結果をこちらに。 結構単純。
上で述べたように、データパーティションは6番目のでっかいパーティション。 ここは、LinuxのSoftwareRAID(md ... Linux Multi-Disk)でRAID0またはRAID1を 構成した上でxfsでフォーマットされている。このmd+xfsという構成に注意。 単純にxfsだけではなくmdが間に挟まっているのが曲者。なんか別のLinuxで mdなしでxfsフォーマットして使おうとすると、「このディスク壊れてるー!」といって HDL2-A自体がエラー吐いて起動を停止するという。そこまでしなくてもいいやん…。
具体的には、md version 0.90が利用されており、パーティション末尾にこんな データがある(xxはUUIDなので削除)。
# dd if=/dev/sda bs=512 skip=$((3907029128-128*(1024/512))) | hexdump -C 00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00009000 fc 4e 2b a9 00 00 00 00 5a 00 00 00 00 00 00 00 |.N+.....Z.......| 00009010 00 00 00 00 xx xx xx xx 88 a0 08 52 01 00 00 00 |...........R....| 00009020 c0 43 2e 74 02 00 00 00 02 00 00 00 06 00 00 00 |.C.t............| 00009030 00 00 00 00 xx xx xx xx xx xx xx xx xx xx xx xx |................| 00009040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| (snip) |
あー、この"fc 4e 2b a9"って並び、見たことあるわー、と思った人は結構なLinux 使い。これは、mdのマジックナンバーなのでした。これが発見できたので、 6番目のファイルシステムはmd version 0.90でフォーマットされていることが 確定した。詳細知りたい人は RAID superblock formats参照。ここはホントよく書いてあって助かる。
このmdマジックナンバーは「パーティション末尾」に存在する。ということは、 パーティション先頭からは実はxfsでそのままフォーマットされているということ。 従って、RAID1の場合、mdを間に挟まなくても、このパーティションは外部Linuxで そのままxfsとしてmount可能。データサルベージの時は何も考えずにmountできるので とても楽。
この領域のxfs_infoの結果を以下に示す。agcountあたり、 性能を期待してか小さく設定されてるようだけど、それ以外はまぁ…普通かな。
# xfs_info /xfs-mntpoint
meta-data=/dev/sdb6 isize=256 agcount=4, agsize=121824316 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=487297264, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal bsize=4096 blocks=32768, version=2
= sectsz=512 sunit=0 blks, lazy-count=0
realtime =none extsz=4096 blocks=0, rtextents=0
|
あとはおまけ、この領域のmdadm --detailの結果も以下に。 一個だけで使ったからdegradedになってるけどまぁ参考までに。
/dev/md0:
Version : 0.90
Creation Time : Mon Aug 12 17:44:56 2013
Raid Level : raid1
Array Size : 1949189056 (1858.89 GiB 1995.97 GB)
Used Dev Size : 1949189056 (1858.89 GiB 1995.97 GB)
Raid Devices : 2
Total Devices : 1
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Wed Aug 21 20:02:20 2013
State : clean, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
UUID : xxxxxxxx:xxxxxxxx:xxxxxxxx:xxxxxxxx
Events : 0.22
Number Major Minor RaidDevice State
0 0 0 0 removed
1 8 22 1 active sync /dev/sdb6
|
上にpartedの出力があるので、判る人にはすぐわかる、HDL2-Aシステムのバックアップ 方法。単体だと無理なので、HDDを引っこ抜いて何かLinuxマシンに接続して、 システム部分(5番目のパーティションまで)をddで読み出せばよい。 HDL2-Aのディスクが/dev/sda、バックアップ先を/mnt/backup/HDL2-A40-system.img だとすると、以下のようなコマンドでバックアップ可能。非圧縮で4.2GB。 bzip2を使うのは単なる趣味。これで800MB程度(ファームウェア1.07の場合。1.05だと 550MB程度だった)の大きさのファイルが出来た。
# dd if=/dev/sda bs=512 count=8650832 | bzip2 -c > /mnt/backup/HDL2-A40-system.img.bz2 |
あとは、mdのメタデータも一応バックアップしておこう。md 0.90の場合、メタデータは RAIDデバイスの末尾128KB〜のどこか(デバイスサイズを64KBアラインしたところ)に 格納されている4KBのデータなので、以下の操作でバックアップ可能。 RAID0の時は二つのデバイス両方取得しておくこと。
# dd if=/dev/sda bs=512 skip=$((3907029128-128*(1024/512))) | bzip2 -c > /mnt/backup/HDL2-A40-md-metadata.img.bz2 |
リストアする時は、以下手順で。 データ部分は別途バックアップしといてくれたまえよ。 以下の手順でもデータ部分はなくならないけど、ユーザ設定とかはバックアップ時の 状態に戻ってしまうため、アクセスできないファイルができちゃうかも。 だから、よくわかってないならデータ部分もバックアップ時のものに戻すのが無難。 メタデータは、サイズが異なるHDDにはリストアできないことに注意(理由が わからん人は、こういうことしちゃダメ!)。
# bzip2 -dc /mnt/backup/HDL2-A40-system.img.bz2 > /dev/sda # partprobe /dev/sda # bzip2 -dc /mnt/backup/HDL2-A40-md-metadata.img.bz2 | dd of=/dev/sda bs=512 seek=$((3907029128-128*(1024/512))) |
実は、システム部分はHDD1とHDD2とで微妙に内容が異なる (バックアップ後のバイナリで確認)。中が見えない(し見る気もない)のでなんとも いえないけれど、異なる以上は両方バックアップを取っておいた方がいいと思う。 一応HDD2のシステムをHDD1にリストアしてHDD1側から起動できることは確認したけど。
まぁ…NASなんだから、NASとして使用しつつ ネットワーク経由でどっかに保存するのが簡単だろう。普通はそれでO.K.。
それとは別に、ファイルシステムとしてなんとかしたいなら、 別途用意したLinuxマシンにHDL2-AのHDDを接続して、6番目のパーティションを xfs_copyコマンドでどっかに 全コピー。xfs_copyコマンドで作るバックアップ(=コピー先)ファイルは sparseになるらしいので、sparse機能が有効なファイルシステム上であれば、 実際のディスク容量は少なくて済む。 ただし、xfs_copyコマンドでは、コピー先にコピー元と全く同じファイルシステムが 作成されるため、パーティション上にコピーする時も パーティションサイズに合わせてファイルシステムサイズを変えては くれないことに注意。コピー後 xfs_growfsすればいいけど。 あとはxfsdumpかなぁ…。 こっちのほうが汎用性は高そうな気が。
いずれにしても、これはRAID1のみの話。RAID0だと、外部Linux上でバックアップ 取ろうとすると、二つのディスクを同時にLinuxに接続してmd有効にした上で 云々しないといけなくて面倒。
システムもHDDも壊れてHDL2-Aが全然起動できなーい!しかしデータサルベージ したーい!というときは、RAID1構成であれば、そのHDDを外部Linuxに接続した上で 以下のように操作することで、 xfs部分が壊滅的に壊れていなければ、外部のLinuxからmountして参照可能。 以下では自作1CDLinuxとknoppixを使ったので/dev/sdaで認識されたとする。
# mount -t xfs -r /dev/sda6 /mnt/hdd # (mountできた) |
XFSのWikipediaの 「欠点」に書いてあるように、ARM Linuxでのxfsジャーナルはx86 or x86_64 Linux 上では復旧できないので、上のコマンドでmountできない場合は、潔くジャーナルを 諦める。
# mount -t xfs -r /dev/sda6 /mnt/hdd mount: Structure needs cleaning (mountできなかった) # xfs_repair -Lv /dev/sda6 (多分エラーが出て/lost+foundにいくつかファイルが移動するが男らしく諦める) # mount -t xfs -r /dev/sda6 /mnt/hdd # (mountできた) |
RAID0の場合は、以下のようにすればmountできるかもしれない(が、未検証)。
# mdadm --assemble /dev/md0 /dev/sda6 /dev/sdb6 # mount -t xfs -r /dev/md0 /mnt/hdd |
以下の条件を満たせば、I-O Dataが提供している純正のものではなくても換装可能。
これらさえ守れば、片方抜いて新しいHDDを挿してフォーマットすればいい。 RAID1ならそれで換装は完了する。RAID0ならデータ部分のフォーマットが必要。
上の条件、特に三番目を書いたのには理由があって、 同じHDD容量が表示(たとえば2TBとか)されていても、 実際にはメーカーによって?微妙に総セクタ数が異なるHDDが存在しているからだ。 なに?「本当か?」だって?よしわかった、証拠見せてやる!
| サイズ | 型名 | サイズ(byte) | セクタ数 (512byte/sector換算) |
|---|---|---|---|
| 1TB | ST31000520AS | 1000204886016 | 1953525168 |
| WD10EADS | |||
| WDH1CS10000N | |||
| HDT72101 | |||
| 2TB | WD20EARS-00MVWB0(WD Green) | 2000398934016 | 3907029168 |
| WD20EZRX(WD Green) | |||
| ST2000DL001 | |||
| ST2000DL003 | |||
| DT01ABA200V | |||
| HDS722020ALA330(0F10311) | |||
| SAMSUNG HD203WI | |||
| 3TB | ST33000651AS | 3000592982016 | 5860533168 |
| HDS5C3030ALA630 | |||
| WD30EFRX(WD RED) | |||
| DT01ACA300 | |||
| 4TB | ST4000DM000 | 4000787030016 | 7814037168 |
| HMS5C4040ALE640(0S03361) |
…あ、あれ?全部同じ…? おっかしーな、前調べた時はSeagateだけちょっと(8セクタくらい)でかい、みたいなことがあったと思ったけど…。どのデータだっけ…。
サイズが同じHDDへの換装方法は、上に述べたとおり。この方法を使うことで、 元のHDDより大きいHDDへは換装できる。しかし、それだと、 たとえ大きなサイズのHDDを挿しても、元から挿さってたHDDより 大きい容量を認識させることができない。元から挿さってたのより大きいHDDを 挿して、しかも容量全部認識させることはできないか?
端的に言えば、可能。
「ファームウェアに換装対策あり」という情報もあるようだが、我輩は1.07へ アップグレード後、以下の手順で換装を実施し、可能であることを確認した。 今のところ不都合はない。REGZAは持ってないのでDLNA/DTCP-IPがち ゃんと動くかどうかは未確認。そもそも3TB HDDx2にしちゃうとHDL2-A6.0相当だから I-O DATAオフィシャルには「未対応」になるのかな。
我輩は別にLinuxシステムを持っていたので、
以下のように操作して3TBに換装してみた。
以下、コピー元の2TB HDD(Seagate ST2000DM001)を「元HDD」、
コピー先の3TB HDD(Toshiba DT01ACA300)を「先HDD」と呼ぶ。
あ、以下の手順ではデータ領域は移行できないので注意。
# parted /dev/sda (snip) (parted) mklabel gpt (parted) u s (parted) mkpart primary 40 1048623 (parted) mkpart primary 1048624 3145783 (parted) mkpart primary 3145784 7340095 (parted) mkpart primary 7340096 7602247 (parted) mkpart primary 7602248 8650831 |
このいずれかの作業を実行しないと、先HDDをHDL2-Aに挿入して起動したときに
NAS OSが起動途中で停止する。
しばらく頑張って起動しているように見えるし、(HDDが無い側のNASのHDD
エラーランプは付くが)挿した側のエラーランプは付かないけれど、いつまで
たってもIPアドレスが割り振られないらしく、外からアクセス不能。
# parted /dev/sda (snip) (parted) remove 6 (parted) u s (parted) mkpart primary 8650832 -1 ※-1は最終セクタを表す (parted) quit |
# mdadm --create /dev/md0 --level=raid1 --raid-devices=2 --metadata=1.0 missing /dev/sda6 |
これで我輩は換装できた。換装後の3TB HDDのpartedの表示結果(セクタ単位)を以下に。 IDがTOSHIBA DT01ACA3で、Physical Sector Sizeが4096B、6番目の パーティションだけが元より大きくなっていることが判るだろうか。
Model: ATA TOSHIBA DT01ACA3 (scsi) Disk /dev/sdd: 5860533168s Sector size (logical/physical): 512B/4096B Partition Table: gpt Number Start End Size File system Name Flags 1 40s 1048623s 1048584s ext3 primary 2 1048624s 3145783s 2097160s primary 3 3145784s 7340095s 4194312s linux-swap(v1) primary 4 7340096s 7602247s 262152s primary 5 7602248s 8650831s 1048584s primary 6 8650832s 5860533134s 5851882303s xfs primary |
ついでにこの領域のmdadm --detailの結果も以下に。 一個だけで使ったからdegradedになってるけどまぁ参考までに。md metadata 1.0で フォーマットされていることがわかる。
/dev/md0:
Version : 1.0
Creation Time : Fri Aug 16 22:01:30 2013
Raid Level : raid1
Array Size : 2925940992 (2790.39 GiB 2996.16 GB)
Used Dev Size : 2925940992 (2790.39 GiB 2996.16 GB)
Raid Devices : 2
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Wed Aug 21 20:06:16 2013
State : clean, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name :
UUID : xxxxxxxx:xxxxxxxx:xxxxxxxx:xxxxxxxx
Events : 15037
Number Major Minor RaidDevice State
0 0 0 0 removed
2 8 22 1 active sync /dev/sdb6
|
あとは、念の為xfs_infoの結果も貼っとこう。projid32bit=0が増えてるが気にしない。 lazy-count=0なのがちょい気になる。 普通にmkfs.xfsするとlazy-count=1になるんだよね…。
# xfs_info /xfs-mntpoint
meta-data=/dev/sde6 isize=256 agcount=7, agsize=121824316 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=731485248, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal bsize=4096 blocks=32768, version=2
= sectsz=512 sunit=0 blks, lazy-count=0
realtime =none extsz=4096 blocks=0, rtextents=0
|
換装手順は、4TB HDDでも8TB HDD(まだ無いけど)でも同じ。 4TB HDDx2へ換装テスト(ただしRAID1のみ)してみたら、問題なくできた。 誰か6TB HDDx2寄付してくれたら、我輩喜んで試すよー!(厚顔)。
なんでこんな複雑な手順が必要なのかというと、先述の通り、データパーティションが md+xfsでフォーマットされているため。このため、HDL2-Aでは 単純な「データパーティションの拡大」は不可能。mdのメタデータが パーティション末尾に存在するので、単純にパーティションを拡大しちゃうと メタデータが参照できなくなってしまうから。失敗している人はこれをちゃんと 把握してなかったんじゃないかなぁ。あ、メタデータにはそのパーティションを /dev/md#使った時のパーティションサイズとかも入っているので、単純に メタデータ位置を動かせばO.K.というワケでもない。結局、(メタデータの UUIDは変わるけど)mdadm --createで作り直した方が楽。
換装後のCrystalDiskMarkは以下の通り。 大きな変化はないが、ランダムアクセスの性能がちょっと 上がってる。HDDごとの傾向が出てて面白い。
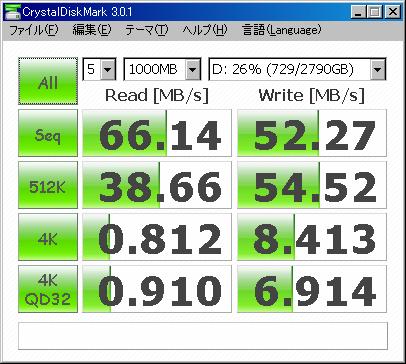
「安定動作こそ我が命!」とかページ頭で書いておきながらこんなことすんなよという そしりはあえて全身で受け止める所存ナリ。全く仰るとおりで。
HDD換装やデータコピーの手順を、Linux上で動作するbashスクリプト化してみた。 これらを使えば、サイズが異なるHDDへの換装やデータコピー(RAID1のみ)とかが簡単に できるようになる。つってもまぁキケンなのはその通りなので、 中を参考にするだけにしといた方がいいかもよ?
フツーのシステムでも1CDLinuxでもなんでもいいから、とにかく rootになれるLinux上で動作するはずなんだが…udev周りで「デバイスを動的に 認識して勝手にmdadm --assembleでスタートしちゃう」という行儀の悪い ディストリビューション(コレやられるとコピー元のHDDのmdのctimeも変更されるので、 RAID崩壊しちゃうんだよね…)では、実行時エラーになることもしばしば。 そういうのでは、事前に「udevadm control --stop-exec-queue」とかでudevを 一時停止しておくと吉。Knoppix 7.0.2 では、udev 止めちゃうと /dev/md* が 自動作成されなくなるので、事前に cd /dev; ./MAKEDEV md とか実行して デバイス作っとかなきゃいけないとか、ディストリビューションごとにそういう 細かい不具合がもりもり。
我輩は、CentOS6(とソレを元にした自作の1CDLinux)上で、上で述べたのコマンドで udevを止めた上で動作確認した。しかし 正直、我輩に聞かれても再現環境がないとなんともできないかもしれないため、 うまいこと動かなくても自分でなんとかするくらいの気概は欲しいところ。 なお、Ubuntuでは動かなかったとの情報を頂きました。ダメじゃん! あと、使ってアナタのシステムが破損しても我輩は一切責任取らないのであしからず。
問題あるなら runlevel 1で実行するか頻繁にOSを再起動してくだされ。 おススメはrunlevel 1か、USB経由で接続してなんかするごとに抜き挿しする、かなぁ。
# sh clear-hdl2-a-disk.sh /dev/クリアするHDDデバイス |
HDL2-Aで使用するために、ディスクを真っ白にするスクリプト。 中のデータを全部消すのではなくて、HDL2-Aで再利用するときのために 最小限のクリアを行う (だから、実行時間は短い。input待ちを除けば一分以内に終わるはず)。 具体的には実行するのは以下の二つ。
HDD上に要らんゴミが残っていると後述のスクリプトでエラーになったりするので、
そういうのを防ぐために、後のスクリプトを使う前には対象HDDをこのスクリプトで
真っ白にしておくことをお勧めする。
また別の用途として、HDL2-AのRAID崩壊時に復旧させるために新たにHDDを挿す時、
そのHDDが新品でない(=中にゴミが残っている)のであれば、
そのゴミが悪さするのを防ぐために、
事前にこのスクリプトを使って新たに挿すHDDを真っ白にする、なんてことにも使用可能。
当然、指定したHDDは真っ白になり、中のデータにはアクセスできなくなるので要注意。 一応大部分のデータは残ってはいるが、アクセスできるようにするのは現実的には無理。 間違ってクリアしちゃったら諦めるが吉。 オマエやれっていわれたら1億円積まれたら考えなくもないレベル。
# sh build-hdl2-a-disk.sh /dev/作成対象HDDデバイス システムイメージ |
データを移行するのではなくて、単純に新しいHDDを買ってきて、そのHDDを HDL2-Aに載せたいなー(データは空でいいから)、という時のために使用する。事前に、 システムイメージ(上で取得したシステム部分のバックアップ(4.2GB、非圧縮またはgz/bz2/xz圧縮))が必要。 実行する内容は以下の通り。
このままではHDL2-A上で使えない。 ちょい面倒だが、HDL2-A上で使うには、以下の手順が必要。
# sh copy-hdl2-a-disk.sh /dev/コピー元HDD /dev/コピー先HDD |
(RAID1でしか使えないけど、)コピー元HDDからコピー先HDDに、HDD内容を全てコピーする。 容量がコピー元・コピー先で異なっていても、コピー先のデータ領域容量が コピー元の実際のデータ量より大きければ問題ない。すなわち、コピー先HDDがコピー元HDDより小さくても、データが入る容量があればいい。 実際のコピーはデータ量分のみ実行されるので、HDD全部ddでコピーするよりは コピー時間も短くて済む。
新しくでっかいHDD買ってきて換装するー、あるいは、バックアップ用に小さなHDD上にデータを取っとくー、とかの時にはとっても便利。 コピー元HDDは変更しない(mdも使わないのでMD headerのctimeも変更されない)ので、 コピー元HDDをそのままHDL2-Aに戻しても、RAID崩壊→再構築されたりしないのも利点。
ただし、コピー先のHDDをHDL2-A上で使用するには、一手間必要。 データ部分のMDのUUIDが異なるため、既存のディスクや同じ方法で取得したHDDとの ミラーリングはできない(違うとみなされて再構築される)からだ。 やるとRAID崩壊して再構築が走るはず(RAID1ならデータは壊れたりはしないはず)。 だから、作成したコピー先HDDをHDL2-A上で使うには、以下の手順を実行すること。 ちょい面倒。
これでDLNA/DTCP-IPで書いたデータまで引き継げるかどうかは不明。 フォーマットしない限り、引き継げないんじゃないかしらん…。 誰かがREGZAくれたら試せるんだけどなー…(チラッ)。 とはいえ、我輩はフツーにPCのデータ領域としてしか使ってない(=DLNA/DTCP-IPで データを保存していない)ので、別にDLNA/DTCP-IPで保存したデータが読めなくなっても 問題ない問題なーい。
なお、コピーにかかる時間はテキトーに(50MB/s転送できるものとして)計算しており、 あんま信じないように。
上の copy-hdl2-a-disk.sh 中で実行してるのは以下のような手順。 データ領域(六番目のパーティション)を、xfs_copy で全部を元HDD→先HDDへ コピーした後、先HDDの容量が違う(大きい)場合のために、xfs_growfsで パーティションをいっぱいまで広げる。
まぁしかし…これやるくらいなら、フツーにNASとして動かしつつ、 ネットワーク経由でコピーした方がいいと思うけどねぇ。
# xfs_copy /dev/sdb6(=元HDD) /dev/sda6(=先HDD) # mdadm --assemble --run /dev/md0 /dev/sda6(=先HDD) # mount -t xfs /dev/md0 /mnt # xfs_growfs /mnt # umount /mnt # mdadm --stop /dev/md0 |
md metadata 0.90だと、普通kernel-2.6では認識できる上限が2TBのはず。 3TB HDDを乗せるとおかしなことになっちゃう気がするのだが、 HDL2-A6.0は大丈夫なんだろうか。 だから上では強制的に1.0を使うようにしているのだけれど。
md ver 0.90で一デバイスあたり最大4TBまでチェック可能なパッチは こちらにある。 問題点は、sb->size(対象パーティションのセクタ数(512byte単位))が_u32なのに、 それを*2して比較・代入してるために、パーティションが2TBを超える(=セクタ数が 31bitを超える)と計算中に32bit超えちゃうというところ。 上のパッチは、計算元を32bitからsector_t (CONFIG_LBDAF=yなら64bit)にキャストしてから計算することで、 桁あふれを回避するパッチだ。ただし、元々sb->sizeは_u32で固定なので、 だからmd metadata 0.90では1デバイスあたり4TBまでしか認識できない。 md metadata 1.x ではそのあたり改善されて、色々64bit化 されているので大丈夫。バグはあるかもしらんけど。
ファームウェア1.07のkernelは2.6.31.8らしく、 kerne.orgの2.6.31.8のソースコード では上のパッチは適用されていなかったので、I-O DATAが独自に対応したので なければ未対応なんじゃ…?現物ソースコード見ないとわかんないけれど。ちうか ソースコード要求するのめんどくさいからこれ以上は見ない! 一方、 3TBのパーティションを元にmd ver 0.90でRAIDを組むと、フツーに組めるけど 使ってるうちに壊れちゃう、みたいな話もある。オーバーフローして 先頭から書き始めてしまって云々みたいな。そりゃそうだろう。コエー!
HDL2-A6.0を持ってる人は、是非mdのメタデータがどうなってるか教えて下さい。 「mdadm --detail /dev/md0」とかやると出てくるから。加えて、RAID1で2TBを 超えたデータを既に持っている人は、問題なく動いているかどうかも是非。 RAID0なら4TB越えかな?
ちなみに、 こういう方法で既に存在するmetadata 0.90を1.0に変更することは可能。 0.90と1.0のmetadata位置が同じことを利用する裏技だけど(だから1.1などへは変換できない)。
HDL2-Aを普通に動かしつつ、別のマシンから、HDL2-Aが外向けにサービスしている ポートが無いか確認してみた。まるでクラッカーみたいな所業。UDPは遅いので 1024まで。 結果見ると、TCPではtelnetもsshも使えないですな。アタリマエか。 なんかUDPは、FW 1.07では開いてるポートが多かったが、 1.09になってから随分減ったね。よもやこのページ監視されてる!?
# nc -z 192.168.1.7 1-9999 Connection to 192.168.1.7 21 port [tcp/ftp] succeeded! Connection to 192.168.1.7 80 port [tcp/http] succeeded! Connection to 192.168.1.7 139 port [tcp/netbios-ssn] succeeded! Connection to 192.168.1.7 427 port [tcp/svrloc] succeeded! Connection to 192.168.1.7 445 port [tcp/microsoft-ds] succeeded! Connection to 192.168.1.7 548 port [tcp/afpovertcp] succeeded! Connection to 192.168.1.7 3689 port [tcp/daap] succeeded! # nc -u -z 192.168.1.7 1-1024 Connection to 192.168.1.7 137 port [udp/netbios-ns] succeeded! Connection to 192.168.1.7 138 port [udp/netbios-dgm] succeeded! Connection to 192.168.1.7 427 port [udp/svrloc] succeeded! |
「全部自己責任」という原則において、皆様からの質問には基本答えない。 でも、ご意見や情報、誤情報訂正要求(根拠つき)などは募集中。 掲示板経由でも メール経由でも構わないのでどうぞ。
暗号化されてる所を云々という話は、アレな上に興味ないから本ページでは扱わないのであしからず。
あー、上で述べた手順やスクリプトで移行したデータが、DLNA/DTCP-IPで使えるかどうかのテストもしたいなぁ。誰かソレがテスト可能なREGZAを恵んでくれまいか。4TB以上のHDD載ってるヤツ。